











Экспорт из InDesign в html-2: тегируем абзацы
В предыдущей статье был рассмотрен пример того, как с помощью скрипта можно передать в формат html локальное форматирование так, чтобы избежать необходимости чистить полученный html-код от ненужных тегов. В этой статье дополним код: расставим в тексте абзацные теги, добавим шапку и «подвал» html и получим таким образом полноценный html-документ, содержащий только необходимую стилевую разметку.
Всегда нужно помнить, что никакой даже самый универсальный скрипт не избавит от проблем, если в вёрстке беспорядок. Поэтому первым делом нужно убедиться, что в тексте используются только необходимые стили, в свойствах которых указаны соответствующие теги. Конечно, со временем, в процессе отладки, можно «научить» скрипт контролировать различные недосмотры вёрстальщика, но для начального этапа написания программы в макете предварительно должен быть наведён полный порядок.
Для работы над скриптом будем использовать макет, в котором используется заголовок статьи, подзаголовки, и списки (ну и основной текст, конечно). Кроме того, в качестве локального форматирования используются курсив, полужирное и «смешанное» (bold italic) начертание.

Необходимые в данной работе параметры абзацных стилей выглядят так:
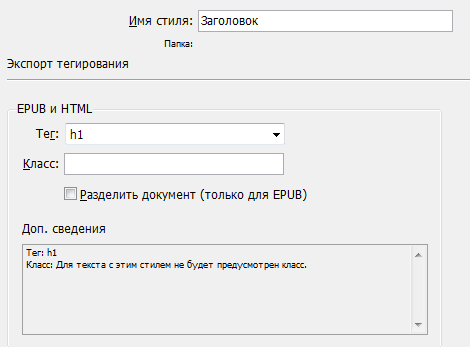
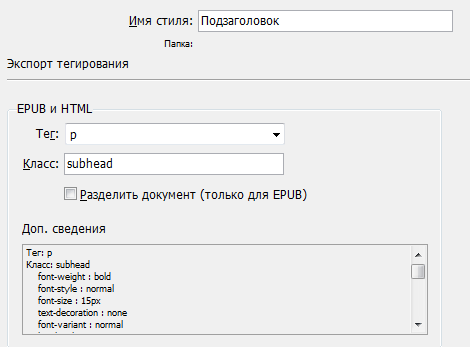
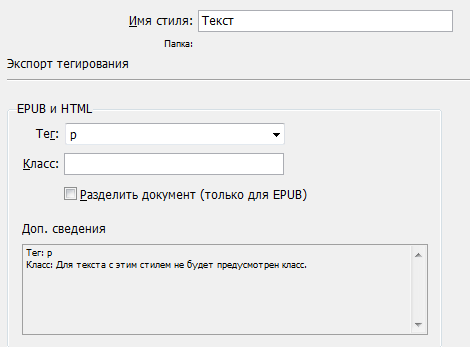
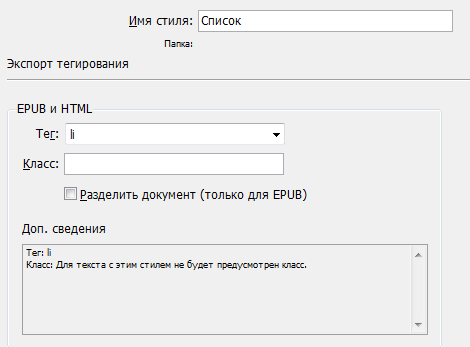
Необходимые нам свойства абзацного стиля в объектной модели:
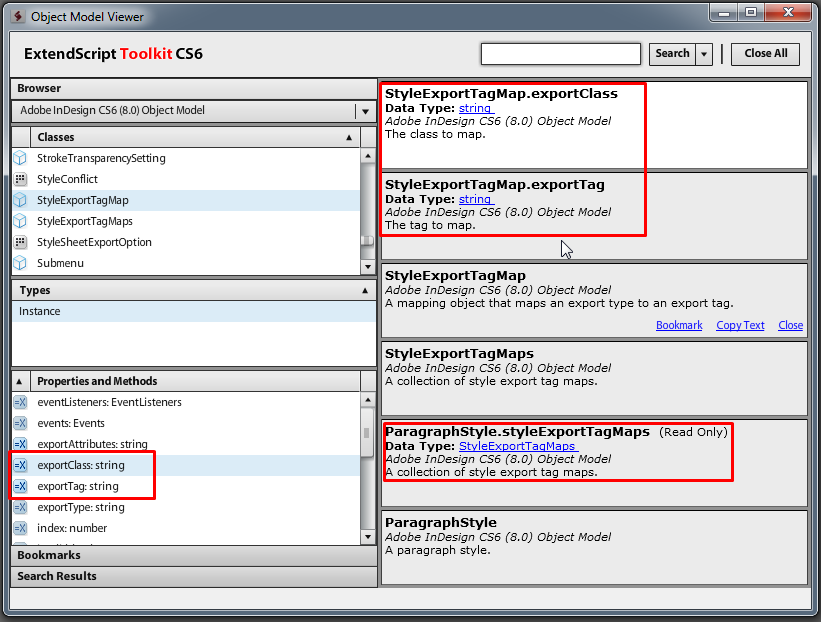
В этой части работать будем с параграфами, поэтому сразу обратимся к ним в текущем материале, в котором установлен курсор.
var doc = app.activeDocument; var s = doc.selection[0].parentStory; s.insertionPoints[-1].contents = "\r"; var p = s.paragraphs;
Обратите внимание на третью строку: она добавляет символ конца абзаца к последнему абзацу. Если этого не сделать, абзац не будет обработан скриптом так, как надо.

Следующим шагом сразу заменим неразрывные пробелы на соответствующий спецсимвол html:
app.findGrepPreferences = app.changeGrepPreferences = null; app.findGrepPreferences.findWhat = "~S"; app.changeGrepPreferences.changeTo = " "; s.changeGrep();
Теперь приступим к расстановке тегов. Для этого обратимся по очереди к каждому абзацу, определим его абзацный стиль, возьмём из его параметров значения тега и класса и припишем абзацу слева и справа соответствующий текст. Перебирать абзацы будем с конца, т.к. будет меняться содержимое текста.
for (i = p.length-1; i >= 0; i--){
var curPS = p[i].appliedParagraphStyle; //Определили абзацный стиль
var ptag = "</"; //В переменной ptag формируем закрывающий тег.
ptag += curPS.styleExportTagMaps[0].exportTag; //Имя тега
ptag += ">"; //Сформировали строку вида "</p>"
p[i].insertionPoints[-2].contents = ptag; //Дописали полученную строку в конец абзаца
var ec = curPS.styleExportTagMaps[0].exportClass; //Класс CSS текущего абзаца (абз. стиля)
p[i].insertionPoints[0].contents = ">"; //Дописали в начале абзаца закрывающую скобку открывающего тега
if (ec != ""){ //Если у стиля есть класс
p[i].insertionPoints[0].contents = SpecialCharacters.DOUBLE_STRAIGHT_QUOTE; //Дописали кавычку
p[i].insertionPoints[0].contents = ec; //Дописали класс
p[i].insertionPoints[0].contents = SpecialCharacters.DOUBLE_STRAIGHT_QUOTE; //Дописали кавычку
p[i].insertionPoints[0].contents = " class = "; //Получили строку вида class = "subhead">
}
p[i].insertionPoints[0].contents = "<" + curPS.styleExportTagMaps[0].exportTag; //Дописали тег и открывающую скобку
//Получили строку вида <p class = "subhead">Текст абзаца</p>"
//или, если класс отсутствует:
//<p>Текст абзаца</p>"
}
Остаётся собрать все три фрагмента кода один за другим в один скрипт, установить курсор в текст и запустить на выполнение. Не забудьте предварительно сохранить документ, чтобы после выполнения можно было восстановить исходные данные из меню "Файл/Восстановить". Если всё было проделано правильно, то после обработки текст примет такой вид:

Остаётся добавить уже реализованную в предыдущей статье обработку локального форматирования и придумать, как дальше быть со списками: абзацные-то теги элементов списка <li>...</li> расставились, но надо ещё теперь добавить тег <ul>...</ul> (в данном случае). Но, всё по порядку.
Решим сначала то, что проще. Добавим в начало кода необходимые переменные, а саму обработку сделаем отдельной функцией (такое решение нам облегчит решение новых задач в следующей статье):
...
var sel = s.textStyleRanges;
var arr = [];
arr ["Bold"] = "strong";
arr ["Italic"] = "i";
arr ["Underline"] = "u";
arr ["Super"] = "sup";
arr ["Sub"] = "sub";
arr ["+"] = "";
gettags(sel);
for (i = p.length-1; i >= 0; i--){
...
//или, если класс отсутствует:
//<p>Текст абзаца</p>"
}
function gettags(sel){
for (i = sel.length-1; i >= 0; i--){
if (sel[i].appliedCharacterStyle.index != 0){
var t = sel[i].appliedCharacterStyle.name.split(" ");
for (j = 0; j < t.length; j++){
if (t[j]!="+"){
try{
sel[i].contents = "<" + arr[t[j]] + ">" + sel[i].contents + "</" + arr[t[j]] + ">";
}
catch(e){}
}
}
}
}
}
Вернём публикацию в исходное состояние (Файл/Восстановить) и запустим скрипт ещё раз. Получим на этот раз такой результат:

Обратите внимание на появившиеся теги <i></i> и <strong></strong> в тех местах, где были применены соответствующие символьные стили.
Ещё раз восстановим исходный вариант файла и закроем вопрос со списками. Здесь, не вдаваясь в долгие объяснения, просто приведу необходимый фрагмент кода.
...
gettags(sel);
var is_li = false; //Определение начала и конца списка
for (i = p.length-1; i >= 0; i--){
var curPS = p[i].appliedParagraphStyle; //Определили абзацный стиль
var ptag = "</"; //В переменной ptag формируем закрывающий тег.
ptag += curPS.styleExportTagMaps[0].exportTag; //Имя тега
ptag += ">"; //Сформировали строку вида "</p>"
//Узнаем последний элемент списка и добавляем ему закрывающий тег </ul>
if ((curPS.styleExportTagMaps[0].exportTag == "li")&&(!is_li)){
ptag += "\r</ul>";
is_li = true; //Мы теперь в списке
}
//Закончили добавлять закрывающий тег списка
p[i].insertionPoints[-2].contents = ptag; //Дописали полученную строку в конец абзаца
//Если мы сейчас в списке, а у текущего абзаца тег уже не элемента списка,
//Добавляем после этого абзаца открывающий тег списка <ul>
if ((is_li)&&((curPS.styleExportTagMaps[0].exportTag != "li"))){
p[i].insertionPoints[-1].contents = "<ul>\r";
is_li = false; //Мы больше не в списке
}
//Закончили добавлять открывающий тег списка
var ec = curPS.styleExportTagMaps[0].exportClass; //Класс CSS текущего абзаца (абз. стиля)
...
И, в заключение (на сегодня), добавим шапку и «подвал» html-документа.
function insertHead(){
var h = "<!DOCTYPE html PUBLIC \"\"-//W3C//DTD HTML 4.01 Transitional//EN\"\" \"\"http://www.w3.org/TR/html4/loose.dtd\"\">\r";
h += "<html>\r";
h += "<head>\r";
h += "<meta content = \"\"text/html; charset = utf-8\"\" http-equiv=\"\"Content-Type\"\">\r";
h += "<title>без названия</title>\r";
h += "<link href=\"\"css/style.css\"\" rel=\"\"stylesheet\"\" type=\"\"text/css\"\">\r";
h += "</head>\r";
h += "<body>\r";
return h;
}
function insertFoot(){
h += "\r</body>";
h += "\r</html>";
return h;
}
Эти две функции нужно разместить в конце кода. А в середине, после всех произведенных операций, указать точки вставки полученных данных:
...
p[i].insertionPoints[0].contents = "<" + curPS.styleExportTagMaps[0].exportTag; //Дописали тег и открывающую скобку
//Получили строку вида <p class = "subhead">Текст абзаца</p>"
//или, если класс отсутствует:
//<p>Текст абзаца</p>"
}
s.insertionPoints[-1].contents = insertFoot();
with (s.insertionPoints[0]){
applyParagraphStyle(doc.paragraphStyles[0]);
contents = insertHead();
}
app.findGrepPreferences = app.changeGrepPreferences = null;
app.findGrepPreferences.findWhat = "\"\"";
var f = s.findGrep();
for (i = f.length-1; i >= 0; i--){
f[i].contents = SpecialCharacters.DOUBLE_STRAIGHT_QUOTE;
}


Если вы обратили внимание, в шапке расставлены сдвоенные кавычки, которые после размещения шапки меняются с помощью GREP на такие, какие нужны, двойные прямые. Это сделано потому, что из строковой переменной кавычки будут размещены такие, какие указаны в настройках используемого словаря, например, «ёлочки». А в html-разметке требуются именно двойные прямые и никакие другие. И, чем возиться каждый раз с этими настройками, в данном случае проще «повесить» эту задачу на скрипт, тем более, что процесс замены скриптом кавычек по скорости абсолютно незаметен для пользователя. По этой же причине в других фрагментах кода, там, где требуется расстановка кавычек, они расставляются отдельными строками кода.
...Экспорт полученного текста делается, как и в предыдущей статье, не как html, а как обычного текста. При этом в поле, где указывается имя файла, можно без проблем указать расширение html и получить нужный результат.
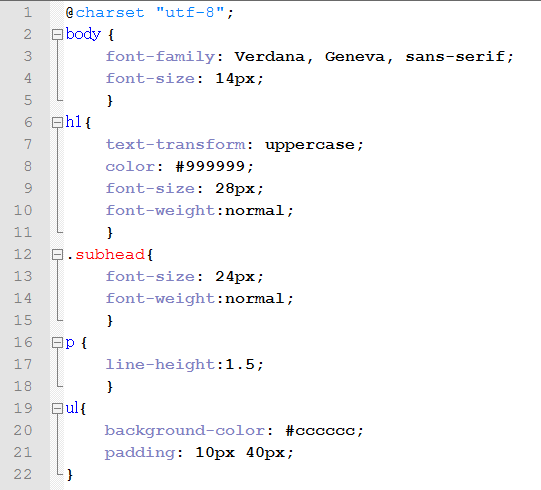
CSS наполняется самостоятельно, например, так:
А результирующий html при таком алгоритме и форматировании будет выглядеть так:



В следующей статье разберёмся с таблицами, т.е. научим скрипт превращать таблицу InDesign в таблицу html с необходимой для правильного отображения html-разметкой. А ещё через статью расставим скриптом ссылки на изображения.
Комментариев нет.
Ещё статьи:
- Быстрое форматирование
- Быстрое вращение разворота
- Перекрёстная ссылка в два клика
- Доступ к скрипту из локализованного меню
- Экспорт из InDesign в html: тегируем символьные стили
- Экспорт из InDesign в html-3: таблицы
- Скрипт не появился в меню, или Ещё раз о локализации
- Экспорт из InDesign в html-4: работа с изображениями и гиперссылками
- Локализованное меню: приключения продолжаются
- Как организовать доступ к списку стилей через Пользовательский интерфейс

