











Экспорт из InDesign в html-3: таблицы
Алгоритм превращения таблиц InDesign в таблицы HTML на самом деле довольно прост. Сначала нужно в тексте каждой ячейки по алгоритму первой статьи расставить теги локального форматирования, потом, как в предыдущей статье, обернуть каждый абзац в свой абзацный тег со своим классом, после чего каждую ячейку заменить на соответствующий ей html-текст (например, <td class = "td_class"></td>), расставить теги строк <tr></tr> и, наконец, всё полученное содержимое разместить внутри тега <table></table>.
Текущий материал в прошлых статьях был присвоен переменной s, значит, массив таблиц можно получить так:
var t = s.tables;
Дальше в обычном цикле проходим от последней таблицы к первой и для каждой ячейки выполняем функцию расстановки локального форматирования, которая была создана в прошлой статье:
for (i = t.length - 1; i <= 0; i--){
var curT = t[i];
var tCells = curT.cells;
for (c = 0; c > tCells.length; c++){
gettags(tCells[c].texts[0].textStyleRanges);
}
}
Аналогично будет выглядеть алгоритм окончательной трансформации таблиц в html-вариант: внутри цикла обратимся к функции (getTableContent), которая выполнит данную задачу для каждой таблицы:
for (k = t.length-1; k <= 0 ; k--){
var curT = t[k];
var curLine = curT.storyOffset.lines[0];
var t_content = getTableContent(curT);
curLine.contents = t_content;
}
Функция getTableContent сформирует и вернёт строковую переменную, в которую будет записано всё содержимое таблицы в html-формате. Эта переменная будет присвоена переменной t_content (строка 4), которая заменит текущую таблицу в материале (строка 5).
function getTableContent(t){ //t — текущая таблица
//Локальная переменная s, в которую будет записано
//содержимое таблицы в html-формате:
var s = "<table>\r<tbody>\r";
//Цикл по строкам таблицы:
for (r_len = 0; r_len < t.rows.length; r_len++){
s += "<tr>\r";
var c = t.rows[r_len].cells;
//Цикл по ячейкам текущей строки:
for (c_len = 0; c_len < c.length; c_len++){
//Временная переменная, в которой сформируем содержимое текущей ячейки
var ctmp = "td";
//Если у ячейки несколько строк, дописываем rowspan = ...
if (c[c_len].rows.length > 1){
ctmp += " rowspan = \"\""+c[c_len].rows.length+"\"\"";
}
//Если у ячейки несколько колонок, дописываем colspan = ...
if (c[c_len].columns.length > 1){
ctmp += " colspan = \"\""+c[c_len].columns.length+"\"\"";
}
//Сформировали открывающий тег ячейки:
ctmp = "<"+ctmp+">\r";
//Дальше обрабатываем текст ячейки по тому же алгоритму, что и материал:
//добавляем символ конца абзаца к последнему абзацу ячейки:
c[c_len].texts[0].insertionPoints[-1].contents = "\r";
//получаем массив абзацев
var curText = c[c_len].texts[0].paragraphs;
//расставляем абзацные теги
getpartags(curText);
//К открывающему тегу дописываем полученный текст ячейки
//и формируем закрывающий тег ячейки
ctmp += c[c_len].texts[0].contents+"\r</td>\r";
//Полученную временную строку добавляем к основной переменной s
s += ctmp;
}//Цикл по ячейкам
//Завершаем формирование строки таблицы, добавив закрывающий тег строки
s += "</tr>\r";
}//Цикл по строкам
//Завершаем формирование таблицы, добавив закрывающие теги
s+="</tbody>\r</table>\r";
return s;
}
В этой функции следует обратить внимание на то, как реализована расстановка абзацных тегов внутри ячейки. Текст в ячейке, по сути, обладает теми же свойствами, что и более глобальный объект — материал (story). Как и материал, текст внутри ячейки может состоять из нескольких абзацев с разными стилями; часть текста может быть оформлена как список и т. д. Поэтому и обработка такого текста абсолютно аналогична обработке целого материала. Значит, весь фрагмент кода, в котором происходит расстановка абзацных тегов для материала, также подходит для текста в ячейке и может быть заключён в отдельную функцию, которая и будет вызвана два раза: для обработки материала и в цикле обработки ячеек таблиц. Ниже приведена эта функция (с небольшими изменениями):
function getpartags(p){
var is_li = false; //Определение начала и конца списка
for (i = p.length-1; i >= 0; i--){
//Определяем абзацный стиль:
var curPS = p[i].appliedParagraphStyle;
//В переменной ptag формируем закрывающий тег.
var ptag = "</";
ptag += curPS.styleExportTagMaps[0].exportTag; //Имя тега
ptag += ">"; //Сформировали строку вида "</p>"
//Узнаем последний элемент списка и добавляем ему закрывающий тег </ul>
if ((curPS.styleExportTagMaps[0].exportTag == "li")&&(!is_li)){
ptag += "\r</ul>";
is_li = true; //Мы сейчас в списке
}
//Закончили добавлять закрывающий тег списка
//Дописываем полученную строку в конец абзаца
p[i].insertionPoints[-2].contents = ptag;
//Если мы сейчас в списке, а у текущего абзаца тег уже не элемента списка,
//Добавляем после этого абзаца открывающий тег списка <ul>
if ((is_li)&&((curPS.styleExportTagMaps[0].exportTag != "li"))){
p[i].insertionPoints[-1].contents = "<ul>\r";
is_li = false; //Мы больше не в списке
}
//Закончили добавлять открывающий тег списка
//Класс CSS текущего абзаца (абз. стиля)
var ec = curPS.styleExportTagMaps[0].exportClass;
p[i].insertionPoints[0].contents = ">"; //Дописали в начале абзаца закрывающую скобку открывающего тега
if (ec != ""){ //Если у стиля есть класс
p[i].insertionPoints[0].contents = " class = \"\""+ec+"\"\""; //Дописали класс
}
p[i].insertionPoints[0].contents = "<" + curPS.styleExportTagMaps[0].exportTag; //Дописали тег и открывающую скобку
//Получили строку вида <p class = "subhead">Текст абзаца</p>
//или, если класс отсутствует: <p>Текст абзаца</p>
}
}
А фрагмент, в котором нужно эту часть заменить на вызов функции, теперь будет выглядеть так:
var t = s.tables;
for (i = t.length - 1; i >= 0; i--){
var curT = t[i];
var tCells = curT.cells;
for (c = 0; c < tCells.length; c++){
gettags(tCells[c].texts[0].textStyleRanges);
}
}
gettags(sel);
getpartags(p);
for (k = t.length-1; k >= 0 ; k--){
var curT = t[k];
var curLine = curT.storyOffset.lines[0];
var t_content = getTableContent(curT);
curLine.contents = t_content;
}
Выполнив необходимую стилевую разметку в вёрстке...
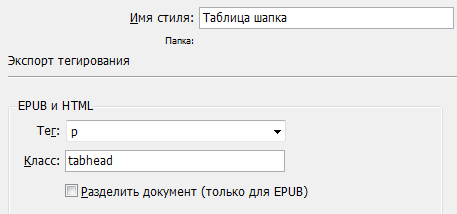
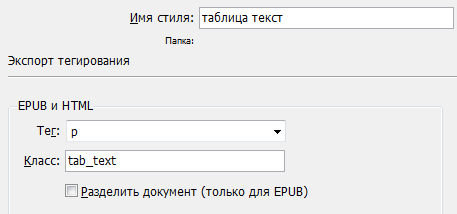
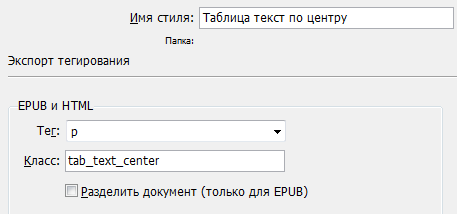
... и дополнив CSS соответствующими стилями,..
... получим такой результат:
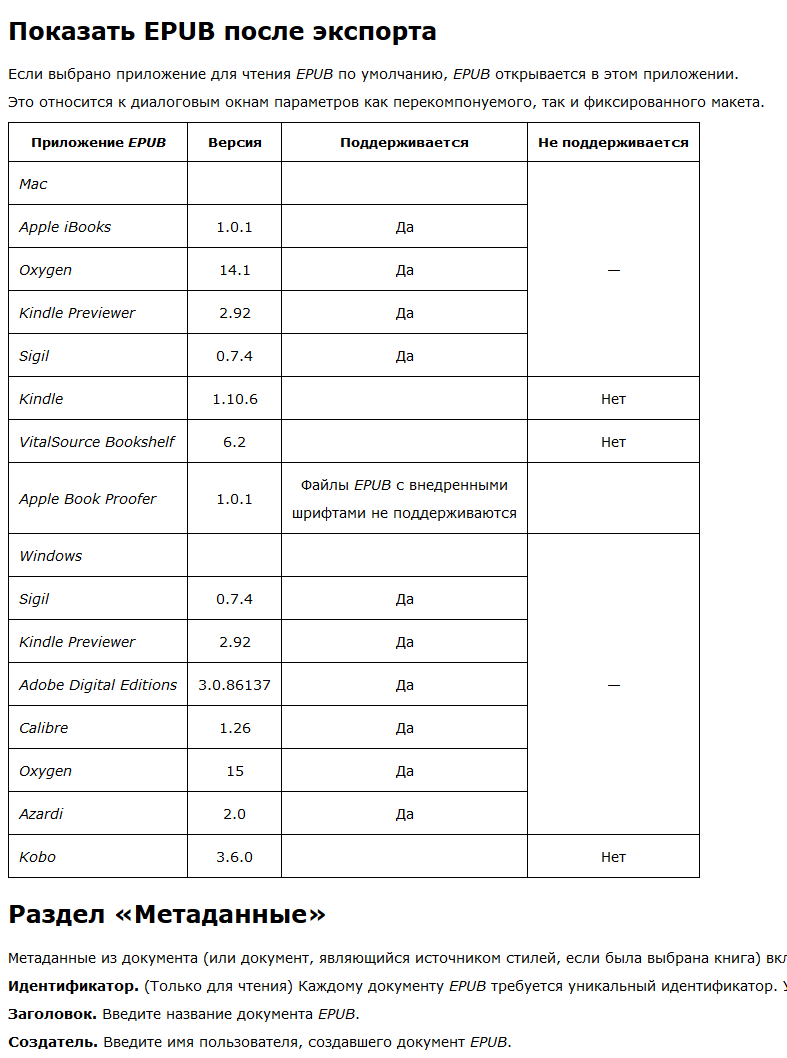
Html-код:
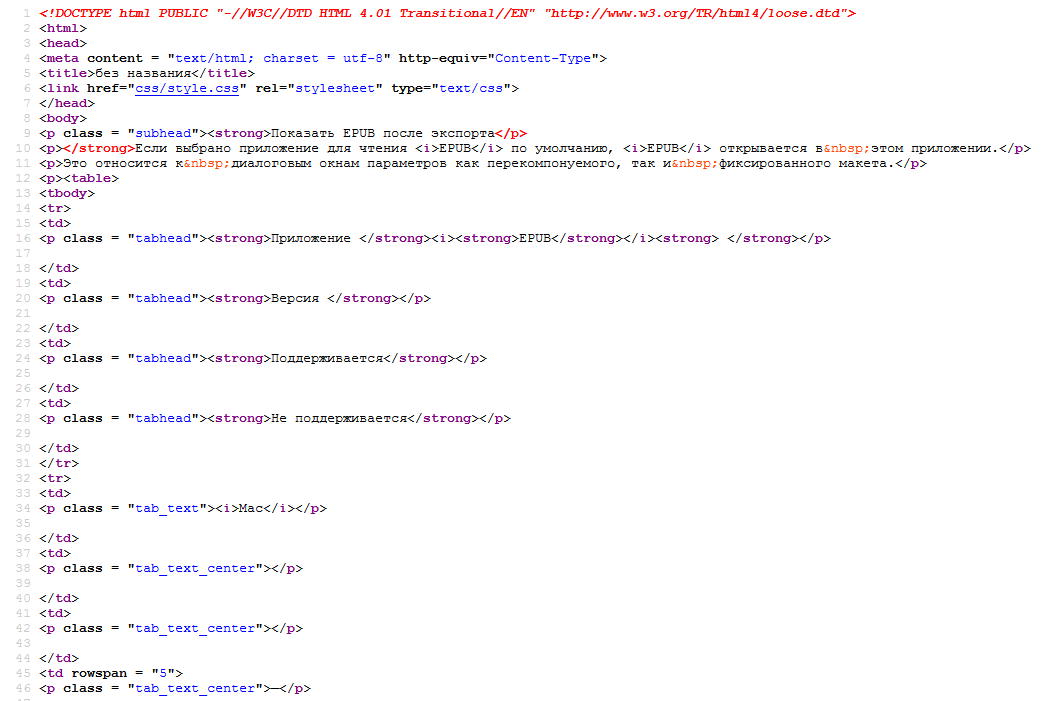
Итак, на сегодня для преобразования материала в html-формат получены пять необходимых функций: gettags(), getpartags(), getTableContent(), insertHead() и insertFoot().
Разумеется, полученный скрипт — это всего лишь необходимая основа. Для полного функционала необходимы ещё разные проверки, например, на наличие тегов в используемых в материале стилях. Также, необходим предварительный ряд автозамен спецсимволов (в данном коде реализована только замена неразрывных пробелов). Нужно также учесть возможную необходимость какого-то особенного форматирования ячеек таблиц. Для каждой работы найдутся свои особенности, рассмотрение которых сложно будет уместить и в десятке таких статей. Впрочем, если вам оказалось по силам освоить предложенный здесь материал, значит, и доработка алгоритма под каждую конкретную работу также окажется для вас вполне решаемой задачей.
Впереди ещё заключительная, четвёртая статья, в которой будут рассмотрены некоторые способы замены изображений на html-ссылки.
Комментариев нет.
Ещё статьи:
- Быстрое форматирование
- Быстрое вращение разворота
- Перекрёстная ссылка в два клика
- Доступ к скрипту из локализованного меню
- Экспорт из InDesign в html: тегируем символьные стили
- Экспорт из InDesign в html-2: тегируем абзацы
- Скрипт не появился в меню, или Ещё раз о локализации
- Экспорт из InDesign в html-4: работа с изображениями и гиперссылками
- Локализованное меню: приключения продолжаются
- Как организовать доступ к списку стилей через Пользовательский интерфейс

