











Export From InDesign to HTML-3: Tables
The algorithm for converting InDesign tables into HTML tables is actually quite simple. First, in the text of each cell, according to the algorithm of the first article, arrange local formatting tags, then, as in the previous article, wrap each paragraph into its paragraph tag with its class, then replace each cell with its corresponding html text (for example, <td class = "td_class"></td>), place the rows tags <tr></tr> and, finally, place all received content inside the <table></table> tag.
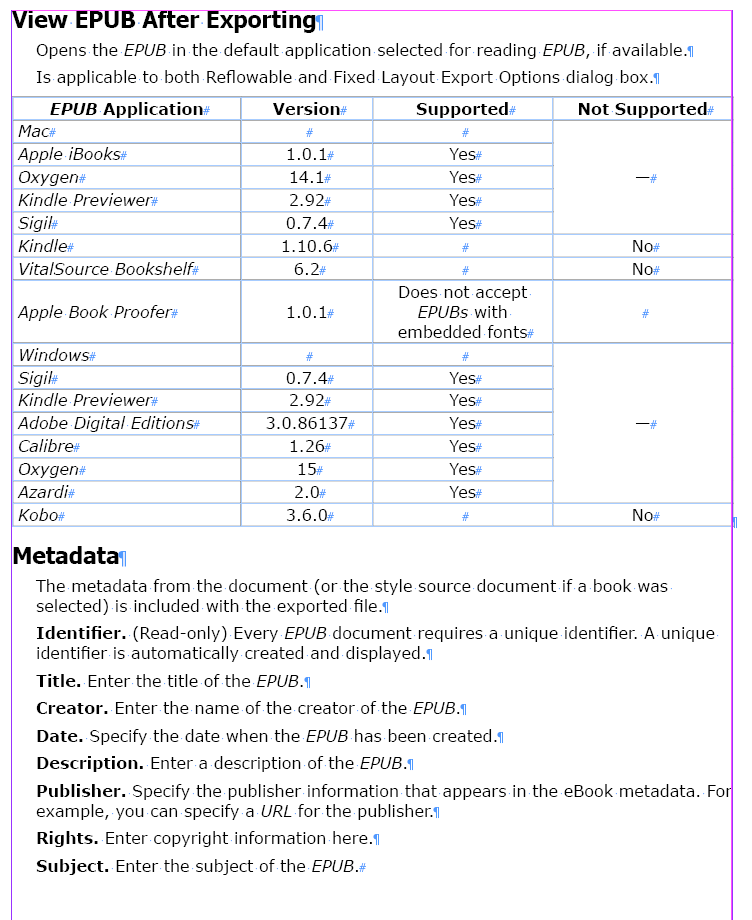
In the previous articles, the current story was assigned to the variable s, so an array of tables can be obtained as follows:
var t = s.tables;
Next, in the usual loop, we go from the last table to the first one and for each cell we perform the function of local formatting, which was created in the last article:
for (i = t.length - 1; i <= 0; i--){
var curT = t[i];
var tCells = curT.cells;
for (c = 0; c > tCells.length; c++){
gettags(tCells[c].texts[0].textStyleRanges);
}
}
The algorithm of the final conversion of the tables into an html-type will look similarly: inside the loop, we turn to the function (getTableContent), which performs this task for each table:
for (k = t.length-1; k <= 0 ; k--){
var curT = t[k];
var curLine = curT.storyOffset.lines[0];
var t_content = getTableContent(curT);
curLine.contents = t_content;
}
The getTableContent() function will generate and return a string variable, in which the entire contents of the table will be written in the html format. This data will be assigned to the variable t_content (line 4), which will replace the current table in the story (line 5).
function getTableContent(t){ //t — current table
//Local variable s, in which the contents of the table will be written in html-format:
var s = "<table>\r<tbody>\r";
//Loop by rows of tables:
for (r_len = 0; r_len < t.rows.length; r_len++){
s += "<tr>\r";
var c = t.rows[r_len].cells;
//Loop by cells in current row:
for (c_len = 0; c_len < c.length; c_len++){
//Temporary variable in which we will form the contents of the current cell
var ctmp = "td";
//If the cell is in several rows (merged cells), append “rowspan = ...”
if (c[c_len].rows.length > 1){
ctmp += " rowspan = \"\""+c[c_len].rows.length+"\"\"";
}
//If the cell is in multiple columns (merged cells), append “colspan = ...”
if (c[c_len].columns.length > 1){
ctmp += " colspan = \"\""+c[c_len].columns.length+"\"\"";
}
//Get the opening cell tag:
ctmp = "<"+ctmp+">\r";
//Next, we process the text in the cell using the same algorithm as for a story:
//add the end of paragraph character to the last paragraph of the cell:
c[c_len].texts[0].insertionPoints[-1].contents = "\r";
//get an array of paragraphs:
var curText = c[c_len].texts[0].paragraphs;
//arrange paragraph tags:
getpartags(curText);
//Add the received text of the cell to the opening tag and form the cell closing tag:
ctmp += c[c_len].texts[0].contents+"\r</td>\r";
//Add the resulting temporary string to the main variable s:
s += ctmp;
}//Close the loop by cells
//Complete the getting of the table row by adding the closing tag of the row:
s += "</tr>\r";
}//Close the loop by rows
//Complete the formation of the table by adding closing tags:
s += "</tbody>\r</table>\r";
return s;
}
In this function, you should pay attention to how the arrangement of paragraph tags inside the cell is implemented. The text in the cell, in fact, has the same properties as the more global object — the story. Like a story, the text inside a cell can consist of several paragraphs with different styles; part of the text can be marked up as a list, etc. Therefore, the processing of such text is absolutely similar to the processing of the whole story. This means that the entire code fragment, in which the indentation of paragraph tags for the story takes place, is also suitable for the text in the cell, and can be enclosed in a separate function, which will be called upon twice: for the processing of the story and in the table cells processing loop. The following is this function (with minor changes):
function getpartags(p){
var is_li = false; //Definition of the beginning and end of the list
for (i = p.length-1; i >= 0; i--){
//Define paragraph style:
var curPS = p[i].appliedParagraphStyle;
//In the variable “ptag” form the closing tag.
var ptag = "</";
ptag += curPS.styleExportTagMaps[0].exportTag; //Tag name
ptag += ">"; //Formed a string like "</p>"
//Recognize the last element of the list and add a closing tag </ul> to it
if ((curPS.styleExportTagMaps[0].exportTag == "li")&&(!is_li)){
ptag += "\r</ul>";
is_li = true; //We are now “in the list”
}
//Finished adding a closing list tag
//Add the resulting line to the end of the paragraph
p[i].insertionPoints[-2].contents = ptag;
//If we are now in the list, and in the current paragraph, the tag is no longer a list item,..
//…then add after this paragraph the opening tag of the list <ul>
if ((is_li)&&((curPS.styleExportTagMaps[0].exportTag != "li"))){
p[i].insertionPoints[-1].contents = "<ul>\r";
is_li = false; //We are no longer “in the list”
}
//Finished adding a list opening tag
//CSS class of the current paragraph (paragraph style)
var ec = curPS.styleExportTagMaps[0].exportClass;
p[i].insertionPoints[0].contents = ">"; //Add a closing bracket for the opening tag at the beginning of the paragraph
if (ec != ""){ //If style has class
p[i].insertionPoints[0].contents = " class = \"\""+ec+"\"\""; //Added class
}
p[i].insertionPoints[0].contents = "<" + curPS.styleExportTagMaps[0].exportTag; //Added a tag and an opening bracket
// Got a string like <p class = "subhead">Paragraph content</p>
// or if class is absent: <p>Paragraph content</p>
}
}
And the fragment, in which this part needs to be replaced with the function call, will now look like this:
var t = s.tables;
for (i = t.length - 1; i >= 0; i--){
var curT = t[i];
var tCells = curT.cells;
for (c = 0; c < tCells.length; c++){
gettags(tCells[c].texts[0].textStyleRanges);
}
}
gettags(sel);
getpartags(p);
for (k = t.length-1; k >= 0 ; k--){
var curT = t[k];
var curLine = curT.storyOffset.lines[0];
var t_content = getTableContent(curT);
curLine.contents = t_content;
}
After completing the necessary styles editing in the layout...
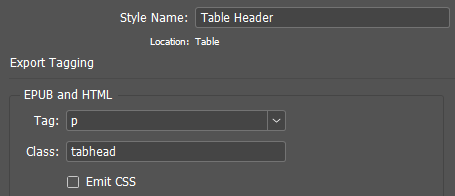
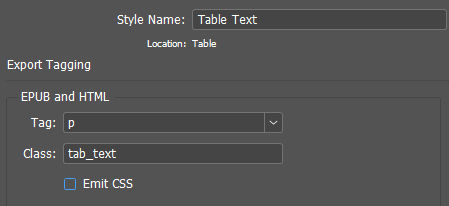
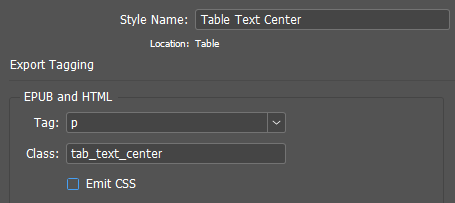
... and adding the appropriate styles to the CSS,..
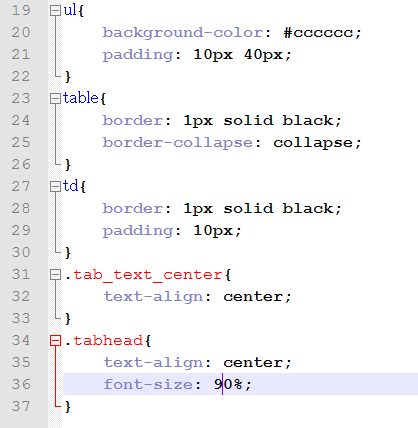
... we get this result:
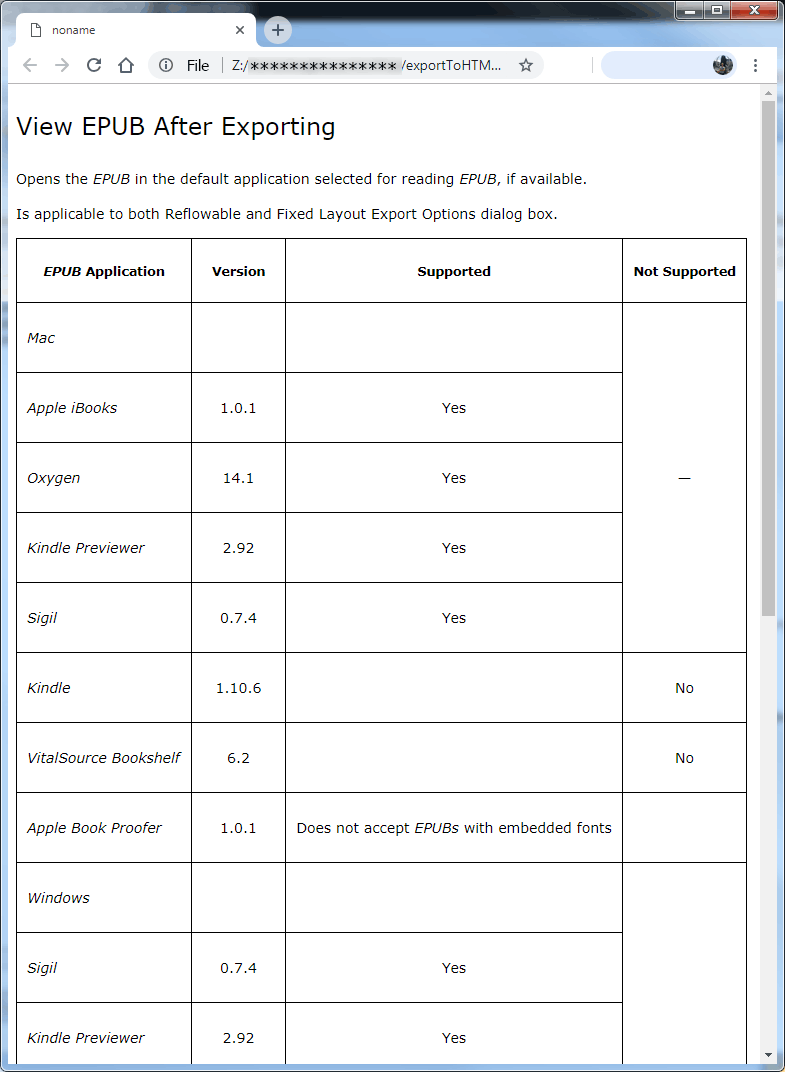
Html-code:
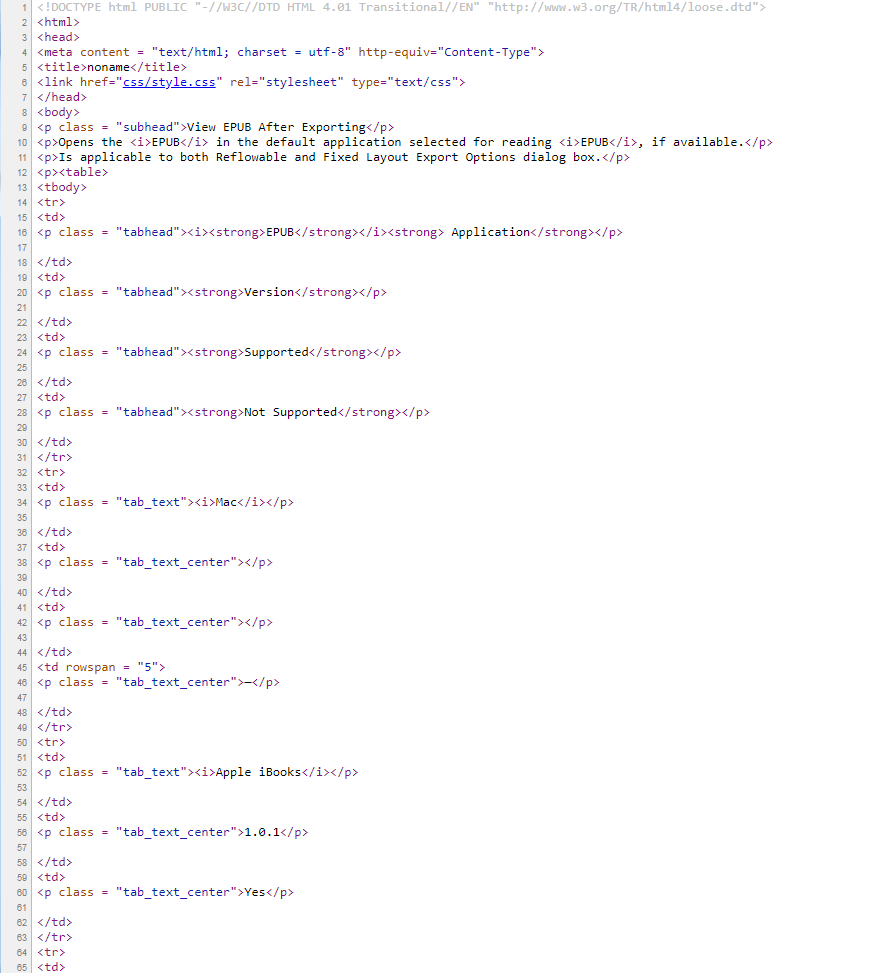
Now, five necessary functions are obtained for converting story into the html format: gettags(), getpartags(), getTableContent(), insertHead() and insertFoot().
Of course, this script is just the necessary foundation. For full functionality, additional checks are needed, for example, checking for the presence of tags in the styles used in the story. Also, a preliminary series of auto-replacements of special characters is necessary (in this code only the replacement of non-breaking spaces is implemented). It is also necessary to take into account the possible need for some special formatting of table cells. For each work, there are specific features, the consideration of which will be difficult to fit in a dozen of such articles. However, if you were able to master the material proposed here, it means that the refinement of the algorithm for each specific work will also be a quite solvable task for you.
There is still the final, fourth article, in which some ways of replacing images with their html representation, as well as the placement of hyperlinks, will be considered.
No comments.
Other articles:
- Quick formatting
- Quick Spread Rotate
- Cross-Reference — in Two Clicks
- Access to the script from the localized menu
- Export From InDesign to HTML: How to Tag Character Styles
- Export From InDesign to HTML-2: How to Tag Paragraphs
- The Script Did Not Appear In the Menu, or One More Time About the Localization
- Export From InDesign to HTML-4: What to Do With Images and Hyperlinks
- Localized Menu: the Adventure Continues
- How to Access the List of Styles Through the User Interface

